
Text Editor Data Structures: Rethinking Undo
Undo and redo have been a staple operation of text editors probably since the first typo was ever made, yet there has not been a lot of innovation around refining the idea of what undo and redo could be. Let’s explore what I mean…
On The Subject of Undo
Undo
In order to understand how to change undo we first need to understand what the fundamental operation of ‘undo’ is supposed to do. I have always learned best through example so let’s assume you start with the string "Hello" and you start typing the sequence " World!":
Hello
In the scenario above, when the undo operation is invoked (typically CTRL+z) what is the typical expectation? There are a myriad of possibilities:
- Undo would delete the entire string
" World!"since it was all part of the same insert operation. - Undo would delete only the last character added,
'!' - Undo would delete the sequence of characters within some time threshold of each keystroke.
There are many approaches to what the undo operation should do and each one has its own merits. The approach I use is close to #1 where the undo operation will undo blocks of the same style of edit. I find this approach to be useful for my workflow. If you are interested in reading a bit more about how popular text editors more concretely implement undo/redo I encourage you to check out Undo/redo implementations in text editors by Matt Duck who very carefully breaks down the approaches of several editors.
There are a few properties of undo that are very nice to have:
- The undo operation should create a corresponding redo operation, more on redo later.
- If undo is applied to the beginning of edit history, the system should report that an undo is not possible and do nothing as a result.
- If you undo (or redo) to the point of the last save of the document the system should recognize that there is nothing to save.
Having #3 is very important to me because it helps me understand where my last ‘committed’ work was during an edit session. It seems like a small “nice to have feature” but the system recognizing various points in history is essential for the feature we’re about to implement.
Redo
Redo is really quite similar to undo in many ways. Let’s take our example of "Hello World!", and apply an undo operation (using the preferred implementation above):
Hello
Redo is the complement to undo and it should perform the same operation that the undo operation just removed. Since there’s a dependency on undo in order to redo it implies that the redo operation cannot be applied on a document which has had no undo operations performed. Furthermore, a redo operation should inherit all the same properties that undo has, e.g. the system should be aware of redo operations as a moment in time rather than a regular operation.
Perils of Undo and Redo
Undo and redo are fantastic operations to have in our editor toolbox, in fact in the way I edit documents today I would argue that undo and redo are a fundamental operation. There are some drawbacks in the way that undo and redo tend to work in most text editors though. To help illustrate what I mean, let’s go back to our "Hello World!" example one more time:
Hello
If we apply undo to remove " World!" and start typing again, most editors will remove the redo state. There are some interesting approaches to help combat this problem, one that comes to mind is the Emacs undo system which keeps undo operations in a separate buffer after you edit again so you can undo that undo and get back to the point where you can redo after an initial undo.
To get a better idea of exactly what happens in most editors, let’s see a small graph of the situation above:
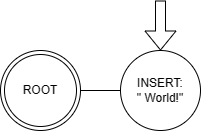
In our initial state, all we’ve done is inserted the text " World!". When we apply the undo operation we get:
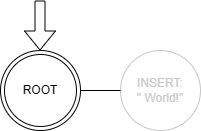
However, after we insert the new string " Cameron!" we end up orphaning the original " World!" node because the history in most editors is intended to be linear:
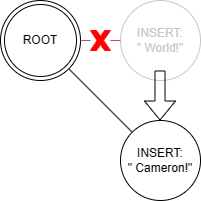
Perhaps with fredbuf we could do better…
Rethinking Undo
Basic Idea
Since fredbuf is a purely functional data structure, we have the ability to very cheaply store any reference to an editor buffer state. So what if we created a graph out of it? What if instead of having a linear list of undos and redos that fredbuf currently has as a builtin, perhaps we could manage a graph of editor states ourself so we could then use some kind of system of UI to navigate it and ‘snap’ back to any of these states.
Imagine we now store the undo/redo data in the following type of structure:
struct UndoRedoNode;
using UndoRedoNodePtr = std::unique_ptr<UndoRedoNode>;
using UndoRedoChildren = std::vector<UndoRedoNodePtr>;
struct UndoRedoNode {
UndoRedoChildren children;
PieceTree::RedBlackTree point;
};
Using the definition above, we can create a graph of undo/redo nodes. There might be a question of, why do we need children to be an array? This comes back to our last example where we showed the string " Cameron!" inserted. If the undo operation were applied yet again and a new string entered, we would create yet another branch at the root node, so we need the capability of the structure above to refer to all possible states.
Visualization
Now that we know how we need to model the data, how do we view it? Graph visualization is a massive topic and there are many intuitive ways to view various types of graphs. The graph we are building with our undo data is closer to a tree (but we can talk about how to turn this into something like a DAG in the future). While editing I have always found it useful to associate timestamps with historical data, as they help me get a better idea for roughly what that change might have been, so visualizing the time the change was made is sensible to me. Additionally, since the tree is a sequence made over time it made sense to me to lay out the tree horizontally with branches moving towards the right of the screen, somewhat like a git branch structure visualization.
When looking at an undo graph in particular it is generally not sufficient for me to simply see the nodes, I also need to see what those nodes contain so I can make an informed decision about whether or not I actually want to apply that undo/redo operation. Enter, the diffing method. The most natural way for me to see deltas in edits is good ol’ diff. Let’s look at a diff of adding " World!" to "Hello":
-Hello
+Hello World!
Since I work with git extensively, this is exactly the kind of thing I want to see in the UI as I navigate from the current edit to some other edit in the past. It allows me to reason about the changes the jump will cause. This means there is only one last problem to solve: implementing the diff algorithm in the editor for various types of snap points. Luckily for us, there is a fantastic series of posts by James Coglan (“The Myers diff algorithm”) which goes over all the gory details of how to implement the popular Myers diff algorithm—I can’t recommend this series enough for anyone interested in implementing their own diff algorithm.
Putting It All Together
Now that we have the data structure and the visualization strategy down, let’s see how it looks all together. Let’s go back to that example where we branched the UI states but had no way to recover the redo of "Hello":
Hello
And here’s that same series of edits made in fred:

When you enter the undo/redo graph mode the editor allows you to navigate to any edit made at any point in time. Additionally, the UI will display the diff from the current edit to the selected node in the upper left-hand corner. It sort of turns your editor into a small source control system!
Conclusion
What did I learn from this?
- Immutable data structures remain a fascinating point of interest for me. They enable so many interesting avenues to solve problems.
- The Myers diff algorithm is incredibly easy to implement, but takes a lot of time to understand what is happening so that you can render it properly.
- It is going to be hard for me to go back to linear undo/redo of most editors
 .
.
If you’re also interested in text editor design, the C++ language, or compilers have a chat with me over on Twitter. I’m always interested in learning and sharing any knowledge that could prove to be useful to others.
Until next time!